

¿Qué es el Machine Learning y Por Qué Debería Importarte?
Qué es el machine learning — y por qué importa tanto — es una pregunta que merece una respuesta honesta. Cada vez que Netflix te recomienda una serie que terminas viendo de un tirón, o cuando tu banco detecta una transacción sospechosa antes de que tú lo notes, hay algo trabajando en silencio detrás de todo eso. No es magia ni ciencia ficción: es matemática aplicada con una consecuencia filosófica profunda. Las máquinas ya no solo ejecutan instrucciones; aprenden de la experiencia.
Esta transformación es tan silenciosa como radical. El machine learning no ocupa titulares a diario, pero está detrás de casi todo sistema inteligente que usas. Entender qué es, cómo funciona y cuáles son sus límites no es un lujo técnico: es una forma de ciudadanía digital en el siglo XXI.
A continuación encontrarás una explicación honesta y sin jerga innecesaria de uno de los conceptos más importantes de nuestra era.
Qué es el machine learning: la definición que nadie te da en términos simples
Machine learning —o aprendizaje automático— es una rama de la inteligencia artificial que permite a los sistemas mejorar su desempeño a través de la experiencia, sin ser programados explícitamente para cada tarea.
El programador clásico escribe reglas. El ingeniero de machine learning, en cambio, le da al sistema datos y le dice: “Tú encuentra las reglas.”
Imagina que quieres enseñarle a una computadora a reconocer fotos de gatos. El enfoque tradicional sería escribir miles de reglas: si tiene orejas puntiagudas, si tiene bigotes… El enfoque de machine learning es radicalmente distinto: le muestras un millón de fotos etiquetadas y el sistema extrae los patrones por sí mismo.
Esta diferencia tiene implicaciones enormes: los sistemas de machine learning pueden descubrir patrones que los humanos nunca hubieran podido articular.
¿De dónde viene esta idea?
Para entender qué es el machine learning en profundidad, ayuda conocer su historia. El término fue acuñado por Arthur Samuel en 1959, quien desarrolló un programa que aprendía a jugar ajedrez mejorando con cada partida. Pero fue en los años 2000, con la explosión del big data y el aumento del poder computacional, cuando el machine learning pasó de ser una promesa académica a una tecnología que transforma industrias enteras.
"Los datos son el nuevo petróleo." — Clive Humby, matemático y científico de datos, 2006. El machine learning es el motor que refina ese petróleo.
Cómo aprende una máquina: los tres tipos principales
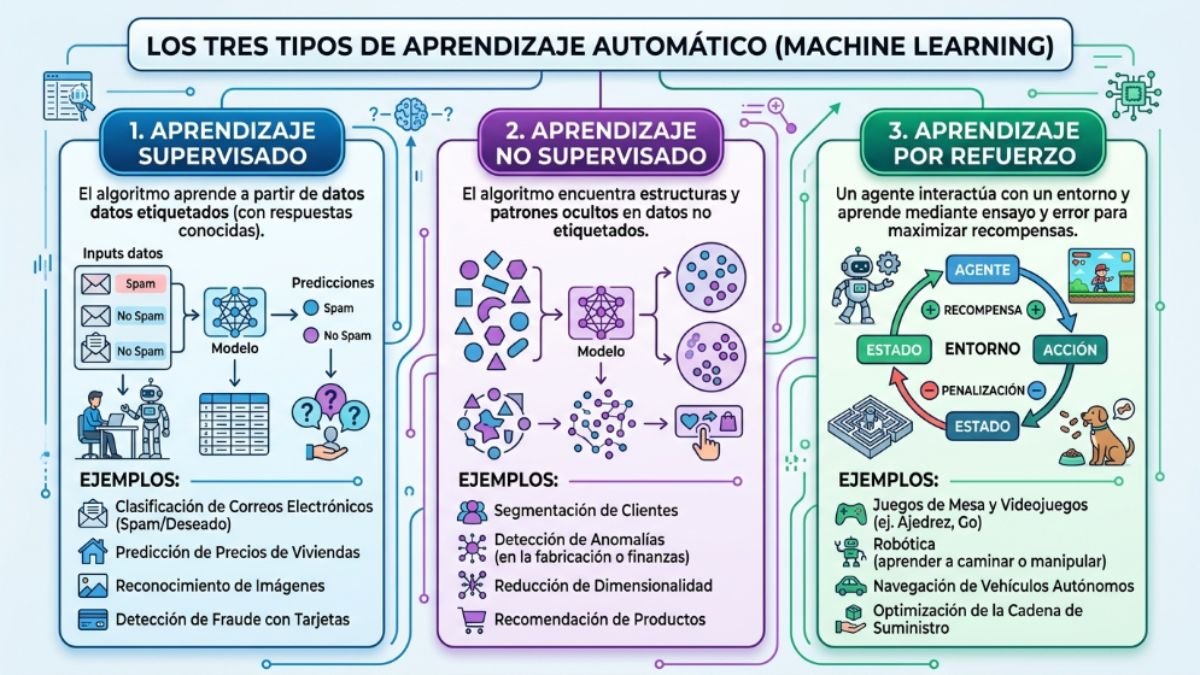
No todo el machine learning es igual. Existen tres paradigmas fundamentales, cada uno con su propia lógica de aprendizaje.
Aprendizaje supervisado
Es el más común. El sistema aprende con datos etiquetados: ejemplos donde ya sabemos la respuesta correcta. Un modelo de detección de spam aprende revisando miles de emails clasificados como “spam” o “no spam”. Con el tiempo, generaliza esos patrones a emails nuevos.
Aplicaciones concretas:
- Reconocimiento de imágenes médicas
- Predicción de precios inmobiliarios
- Detección de fraude financiero
Aprendizaje no supervisado
Aquí no hay etiquetas. El sistema recibe datos y debe encontrar estructura por sí mismo. Es como darle a alguien una colección de música sin géneros y pedirle que la organice: descubrirá agrupaciones naturales sin que nadie le haya dicho qué buscar.
Aplicaciones concretas:
- Segmentación de clientes en marketing
- Detección de anomalías en ciberseguridad
- Sistemas de recomendación de contenido
Aprendizaje por refuerzo
El sistema aprende por prueba y error, recibiendo recompensas o penalizaciones según sus acciones. Es el paradigma detrás de los sistemas que aprenden a jugar videojuegos mejor que cualquier humano, o que optimizan rutas logísticas en tiempo real.
AlphaGo, el sistema de Google DeepMind que venció al campeón mundial de Go en 2016, fue entrenado principalmente con aprendizaje por refuerzo. Su victoria fue considerada un hito histórico: Go tiene más posiciones posibles que átomos en el universo observable.
El proceso real: cómo se entrena un modelo
Detrás de cada sistema de machine learning hay un proceso estructurado que vale la pena entender.
Datos → Preprocesamiento → Entrenamiento → Evaluación → Despliegue
Primero se recopilan grandes cantidades de datos relevantes. Luego se limpian y transforman — el “preprocesamiento” que en la práctica consume el 80% del tiempo de un proyecto real. El algoritmo ajusta sus parámetros internos minimizando el error entre sus predicciones y las respuestas correctas. Se evalúa con datos que nunca ha visto. Finalmente, se despliega en el mundo real.
Este proceso tiene una consecuencia filosófica importante: un modelo de machine learning no “sabe” nada en el sentido humano. Ha optimizado una función matemática para minimizar errores sobre datos históricos. Su inteligencia es estadística, no conceptual.
Dónde está el machine learning en tu vida cotidiana
Probablemente ya interactúas con sistemas de machine learning docenas de veces al día sin saberlo.
Recomendaciones y entretenimiento
Spotify, Netflix, YouTube y Amazon utilizan modelos de filtrado colaborativo para predecir qué querrás consumir a continuación. El 35% de las ventas de Amazon provienen de su motor de recomendaciones, según datos públicos de la empresa. Cuando una playlist “te entiende”, hay un modelo que aprendió tus patrones.
Salud y diagnóstico médico
Los sistemas de análisis de imágenes médicas basados en machine learning han demostrado igualar o superar a especialistas humanos en tareas específicas. Un estudio publicado en Nature en 2020 mostró que un modelo de Google superó a seis radiólogos en la precisión para detectar cáncer de mama en mamografías.
Finanzas y seguridad
Los modelos de detección de fraude analizan miles de variables por transacción en milisegundos para determinar si algo es sospechoso. Visa procesa miles de transacciones por segundo con este tipo de sistemas, bloqueando fraudes antes de que el titular de la tarjeta se dé cuenta.
Lenguaje e IA conversacional
Los modelos de lenguaje que potencian herramientas como ChatGPT son, en su núcleo, sistemas de machine learning masivamente escalados. Predicen la siguiente palabra más probable en una secuencia, pero lo hacen con tal sofisticación que el resultado parece comprensión genuina — aunque sea algo fundamentalmente diferente.
Te gustará saber: ChatGPT vs Gemini vs Claude: ¿Cuál es Mejor en 2026?
🔍 Lo que nadie te dice sobre el machine learning
Existe una narrativa dominante sobre el machine learning que merece ser cuestionada: se nos presenta como un proceso neutral y objetivo — datos entran, verdad sale. Pero los datos no son neutrales; son el reflejo de un mundo históricamente desigual.
El caso más documentado es el de COMPAS, un sistema usado en tribunales de Estados Unidos para predecir reincidencia criminal. Una investigación de ProPublica en 2016 encontró que el sistema era sistemáticamente más propenso a clasificar erróneamente como “alto riesgo” a personas negras en comparación con personas blancas. El machine learning había aprendido y escalado un sesgo histórico como si fuera una verdad estadística.
Hay otro ángulo poco explorado: la opacidad. Muchos modelos de alto rendimiento son “cajas negras”. Pueden predecir con 95% de precisión, pero nadie — ni sus propios creadores — puede explicar exactamente por qué tomaron una decisión específica. Esto plantea preguntas filosóficas serias sobre responsabilidad, transparencia y confianza en sistemas que afectan vidas reales.
"El peligro no es que los ordenadores empiecen a pensar como los seres humanos, sino que los seres humanos empiecen a pensar como los ordenadores." — Daniel Dennett, filósofo de la mente
Las limitaciones reales que los evangelistas de la IA no mencionan
El machine learning tiene fronteras concretas que vale la pena conocer.
Necesita datos masivos.
Los humanos podemos aprender a reconocer un elefante viendo tres fotos. Un modelo típico necesita miles. Esto limita su aplicabilidad en dominios donde los datos son escasos o difíciles de etiquetar.
No generaliza bien fuera de su distribución.
Un modelo entrenado para diagnosticar enfermedades en un hospital de Estados Unidos puede fallar significativamente cuando se aplica en hospitales de otro país con diferentes demografías o equipos de imagen. Esta fragilidad es subestimada con frecuencia.
No razona; correlaciona.
El machine learning es extraordinariamente bueno encontrando patrones, pero no comprende causas. El ejemplo clásico: un modelo podría aprender que “llevar paraguas” correlaciona con lluvia y concluir que los paraguas causan la lluvia. Sin contexto humano, la correlación se convierte en pseudo-causalidad.
Consume energía de forma masiva.
Entrenar los modelos de lenguaje más grandes tiene una huella de carbono equivalente a cientos de vuelos transatlánticos, según investigaciones del grupo de IA de la Universidad de Massachusetts Amherst. La sostenibilidad del ML es un debate que apenas comienza.
Conclusión
El machine learning no es una tecnología del futuro. Es la infraestructura invisible del presente. Está en los sistemas de salud, en las finanzas, en el entretenimiento, en la justicia. Y seguirá expandiéndose hacia cada dominio donde existan datos y decisiones repetibles.
Entenderlo no es un privilegio reservado para ingenieros. Es una necesidad para cualquier persona que quiera participar con consciencia en el debate sobre cómo queremos que la IA moldee nuestras sociedades. Los ciudadanos informados hacen mejores preguntas a quienes diseñan estos sistemas.
La pregunta que vale la pena hacerse no es “¿qué puede hacer el machine learning?” sino “¿qué queremos que haga, para quién y bajo qué condiciones?”
¿Qué aspecto del machine learning te genera más curiosidad o preocupación? Te invitamos a explorar nuestro artículo sobre los riesgos de la inteligencia artificial para seguir el hilo de esta reflexión.
Preguntas Frecuentes sobre ¿Qué es el Machine Learning
¿El machine learning y la inteligencia artificial son lo mismo?
No exactamente. La inteligencia artificial es el campo más amplio que busca crear sistemas capaces de realizar tareas que normalmente requieren inteligencia humana. El machine learning es una subcategoría de la IA — específicamente la que utiliza datos y algoritmos para aprender sin ser programada explícitamente para cada tarea. Todo machine learning es IA, pero no toda IA es machine learning.
¿Se necesita saber matemáticas para entender el machine learning?
Para comprenderlo conceptualmente y usarlo con herramientas modernas, no. Para construir modelos desde cero, sí se necesitan conocimientos de estadística, álgebra lineal y cálculo. Existen plataformas como AutoML de Google o Azure Machine Learning que permiten aplicar machine learning sin conocimientos matemáticos profundos.
¿Cuál es la diferencia entre machine learning y deep learning?
El deep learning es una subcategoría del machine learning que utiliza redes neuronales artificiales con muchas capas (de ahí “deep” o profundo). Es especialmente eficaz en tareas con datos no estructurados como imágenes, audio y texto. Los modelos de lenguaje como GPT son ejemplos de deep learning aplicado a escala masiva.
¿El machine learning puede equivocarse?
Sí, y frecuentemente. Los modelos tienen tasas de error que varían según la tarea y la calidad de los datos de entrenamiento. Pueden fallar de formas inesperadas, especialmente cuando encuentran situaciones que difieren de sus datos de entrenamiento. Por eso la evaluación y el monitoreo continuos son partes esenciales de cualquier sistema en producción.
¿Qué datos necesita el machine learning para funcionar bien?
Depende del tipo de tarea, pero generalmente se necesitan datos suficientes en cantidad y representativos de la diversidad del problema real. La calidad de los datos es más importante que la cantidad: datos con sesgos o errores producen modelos con sesgos o errores. “Basura entra, basura sale” es uno de los principios más vigentes del campo.
¿El machine learning va a reemplazar trabajos humanos?
El debate sigue abierto. El consenso actual entre investigadores es que el ML transformará muchos trabajos más que eliminarlos, automatizando tareas repetitivas mientras crea demanda de nuevas habilidades. Sin embargo, el impacto no será uniforme: algunos sectores y perfiles están más expuestos que otros, y la velocidad del cambio importa tanto como su magnitud.
¿Qué es el machine learning en términos simples?
El machine learning o aprendizaje automático es una rama de la inteligencia artificial que permite a los sistemas aprender y mejorar a partir de la experiencia, sin ser programados explícitamente para cada tarea. En lugar de seguir reglas fijas escritas por humanos, los sistemas de machine learning identifican patrones en los datos y ajustan su comportamiento en consecuencia.



