

Qué son los modelos de lenguaje: la tecnología detrás de los chatbots
Cada vez que escribes una pregunta en ChatGPT, le dictas algo a Siri o recibes una respuesta de un asistente virtual, hay una misma tecnología trabajando en silencio: un modelo de lenguaje. Es la base sobre la que se construye casi toda la inteligencia artificial conversacional que usamos hoy — y, sin embargo, pocas personas saben qué es realmente ni cómo funciona.
Comprender qué son los modelos de lenguaje no es un asunto reservado a ingenieros. Es el tipo de conocimiento que cambia la forma en que usas estas herramientas: sabes qué pedirles, qué no esperar de ellas y por qué a veces se equivocan con tanta seguridad. Según un informe del MIT de 2025, los usuarios que comprenden los fundamentos de cómo funcionan los sistemas de IA obtienen resultados significativamente mejores que quienes los usan como cajas negras.
La explicación que sigue no requiere conocimientos técnicos. Requiere curiosidad y disposición a pensar con algo de profundidad sobre una tecnología que ya forma parte de tu vida cotidiana, lo quieras o no.
Vas a encontrar: qué es exactamente un modelo de lenguaje, cómo aprendió a hacer lo que hace, qué ocurre dentro cuando le escribes algo, cuáles son sus límites reales — y una perspectiva que casi ninguna explicación popular se atreve a plantear sobre si estas máquinas realmente “entienden” algo.

Qué son los modelos de lenguaje: una definición que va al fondo
Un modelo de lenguaje es un sistema computacional entrenado para predecir qué palabras o fragmentos de texto tienen más probabilidad de aparecer en un contexto dado. En su forma más simple: dado un texto de entrada, el modelo calcula cuál es la continuación más probable.
Esa definición parece modesta. La realidad es que, cuando ese proceso de predicción se entrena con cantidades masivas de texto — libros, artículos, conversaciones, código, páginas web — y se ejecuta con suficiente capacidad computacional, el resultado es un sistema que puede escribir, razonar, traducir, resumir, responder preguntas y generar código con una competencia que sorprende incluso a sus creadores.
La clave está en la palabra modelo. No es una base de datos que busca respuestas almacenadas. No es un motor de búsqueda que encuentra información existente. Es una representación matemática de patrones del lenguaje humano — una estructura que ha capturado, de alguna forma, cómo las palabras se relacionan entre sí, cómo se construyen los argumentos, cómo fluye la causalidad en el texto.
Definición esencial – Un modelo de lenguaje no almacena respuestas ni busca información. Genera texto prediciendo, token a token, qué viene a continuación según los patrones que aprendió durante el entrenamiento. Esa distinción cambia completamente cómo interpretas lo que hace y lo que no puede hacer.
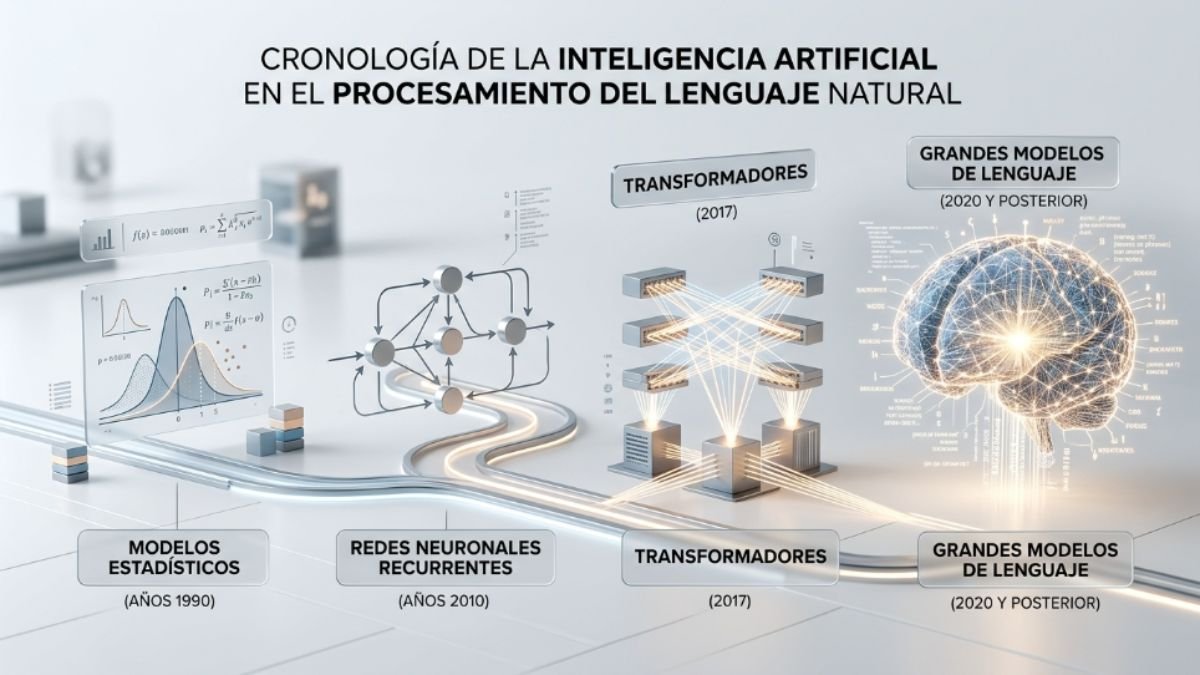
De los correctores ortográficos a los LLM: una historia muy corta
Los modelos de lenguaje no nacieron con ChatGPT. La idea tiene décadas — pero el salto cualitativo de los últimos años es tan grande que la historia anterior apenas resulta reconocible.
Los primeros modelos de lenguaje eran estadísticos: contaban con qué frecuencia una palabra seguía a otra en un corpus de texto y usaban esas probabilidades para predecir la siguiente. El corrector ortográfico de tu teléfono que sugiere la próxima palabra es un descendiente directo de esa idea. Funciona para frases cortas y contextos predecibles. Falla en cuanto la conversación requiere memoria de lo dicho hace tres párrafos.
El cambio decisivo llegó en 2017 con un artículo de investigación de Google titulado “Attention Is All You Need”, que introdujo la arquitectura Transformer. La innovación central era el mecanismo de atención: en lugar de procesar el texto de forma secuencial, el modelo podía considerar simultáneamente todas las palabras de un texto y calcular cuáles eran relevantes para cada parte del contexto. Eso permitió capturar relaciones entre partes distantes de un texto de una forma que los modelos anteriores no podían.
Sobre esa base se construyeron los grandes modelos de lenguaje actuales: GPT, Claude, Gemini, Llama. La diferencia entre ellos y sus antecesores no es solo de tamaño — es de capacidad emergente. A partir de cierto umbral de escala, los modelos empezaron a mostrar capacidades que nadie había diseñado explícitamente: razonamiento, analogías, resolución de problemas, traducción entre idiomas sin haberlos entrenado específicamente para eso.
Cómo funciona un modelo de lenguaje por dentro: tokens, predicción y atención
Cuando escribes algo en ChatGPT o en cualquier chatbot basado en un modelo de lenguaje grande, no envías palabras. Envías tokens.
Qué es un token y por qué importa
Un token es la unidad mínima de texto que el modelo procesa. No es exactamente una palabra — puede ser una sílaba, una palabra completa, un signo de puntuación o incluso un espacio. La palabra “inteligencia” puede dividirse en varios tokens; la palabra “IA” puede ser uno solo. En inglés, una regla aproximada es que 100 tokens equivalen a unas 75 palabras.
Este detalle tiene consecuencias prácticas: los modelos tienen un límite de tokens que pueden procesar en una sola interacción — la “ventana de contexto”. Es el equivalente de la memoria de trabajo. Todo lo que supere ese límite, el modelo simplemente no lo “recuerda” al generar su respuesta.
El proceso de predicción: así genera texto el modelo
Cuando el modelo recibe tu texto, lo convierte en una secuencia de tokens y los transforma en vectores matemáticos — representaciones numéricas que capturan el significado y las relaciones entre conceptos. Sobre esas representaciones, el mecanismo de atención calcula qué partes del contexto son más relevantes para lo que viene a continuación.
El resultado es una distribución de probabilidad: de todos los tokens posibles, cuál tiene más probabilidad de ser el siguiente. El modelo selecciona uno (no siempre el más probable — hay un parámetro llamado “temperatura” que regula cuánta variabilidad se introduce), lo añade al texto y repite el proceso. Token a token, hasta completar la respuesta.
No hay un plan de respuesta previo. No hay una “idea” que el modelo traduce a palabras. La respuesta se construye de izquierda a derecha, un fragmento a la vez, cada uno condicionado por todo lo anterior.

Cómo se entrena un modelo de lenguaje: el aprendizaje a escala
La capacidad de un modelo de lenguaje grande no se programa — se aprende. Y el proceso de aprendizaje es, en esencia, una forma sofisticada de práctica masiva.
El preentrenamiento: leer para predecir
Durante el preentrenamiento, el modelo procesa cantidades enormes de texto — estimaciones para los modelos más grandes hablan de billones de palabras procedentes de libros, páginas web, artículos científicos, código y conversaciones. La tarea es siempre la misma: dado un fragmento de texto con la última parte oculta, predice qué viene a continuación. Cuando se equivoca, los parámetros del modelo se ajustan ligeramente para hacerlo mejor la próxima vez.
Este proceso se repite miles de millones de veces. El resultado no es que el modelo “memorice” el texto — es que desarrolla representaciones internas que capturan estructuras, patrones y relaciones del lenguaje con una profundidad que ningún humano podría programar explícitamente.
El afinamiento: aprender a ser útil
Un modelo preentrenado sabe mucho sobre el lenguaje, pero no sabe cómo ser un asistente útil. El afinamiento — en inglés, fine-tuning con RLHF (Reinforcement Learning from Human Feedback) — es el proceso que enseña al modelo a responder de forma útil, segura y alineada con lo que los humanos esperan. Evaluadores humanos califican diferentes respuestas del modelo, y esas calificaciones se usan para ajustar su comportamiento.
Es la diferencia entre un sistema que sabe todo sobre el lenguaje y uno que sabe además cómo conversar de forma que resulte genuinamente útil para quien lo usa.
| Característica | Modelos anteriores | Modelos de lenguaje grande (LLM) |
|---|---|---|
| Escala de entrenamiento | Millones de palabras | Billones de tokens |
| Arquitectura | Secuencial (RNN, LSTM) | Transformer con atención |
| Ventana de contexto | Cientos de tokens | Decenas a cientos de miles de tokens |
| Capacidades emergentes | Tareas específicas entrenadas | Razonamiento, traducción, código sin entrenamiento explícito |
| Alineación con el usuario | Ninguna o mínima | RLHF — aprendizaje de preferencias humanas |
Para ver cómo estas capacidades se traducen en valor concreto en tu trabajo diario, nuestro artículo sobre IA para aumentar la productividad conecta el funcionamiento técnico con aplicaciones reales — con un método práctico para empezar desde cero
Qué pueden hacer los modelos de lenguaje — y qué no pueden hacer
Comprender los límites de un modelo de lenguaje es tan importante como entender sus capacidades. Los dos errores más comunes son subestimarlos (tratarlos como simples buscadores) y sobrestimarlos (asumir que saben todo y siempre tienen razón).
Lo que hacen bien
- Generar texto coherente y contextualizado: redactar, resumir, traducir, adaptar el tono — tareas donde la calidad del lenguaje es el criterio principal son su terreno natural.
- Razonar sobre patrones: resolver problemas lógicos, analizar argumentos, detectar inconsistencias en un texto, identificar la estructura de un problema.
- Sintetizar información compleja: tomar un documento largo y extraer los puntos clave, comparar posiciones, explicar conceptos con distintos niveles de profundidad.
- Generar variaciones: dado un punto de partida, producir múltiples versiones, alternativas o enfoques distintos del mismo contenido.
Lo que no pueden hacer de forma confiable
- Saber qué ocurrió después de su fecha de corte: los modelos tienen una fecha hasta la que fueron entrenados. Lo que ocurrió después, simplemente no lo saben — y algunos modelos lo inventan con gran seguridad.
- Calcular con precisión: los modelos de lenguaje son malos con la aritmética compleja porque los números son tokens como cualquier otro — no hay un procesador matemático detrás. Para cálculos, necesitan herramientas externas.
- Acceder a información en tiempo real: salvo que tengan herramientas de búsqueda integradas, los modelos no pueden consultar internet ni acceder a datos actualizados.
- Garantizar la veracidad de lo que generan: el modelo produce el texto más probable, no el más verdadero. Las alucinaciones — respuestas incorrectas generadas con confianza — son una limitación estructural, no un error a corregir con una actualización.
⚠️ Atención – Cuando un modelo de lenguaje genera información factual específica — fechas, cifras, nombres, citas textuales — siempre es recomendable verificarla en una fuente independiente. El modelo no distingue entre lo que sabe con certeza y lo que infiere de patrones. Ambos tipos de output suenan igual de seguros.

Si quieres entender cómo esta tecnología evoluciona hacia sistemas que no solo responden sino que actúan de forma autónoma, nuestro artículo sobre qué son los agentes de IA es la lectura que sigue naturalmente a esta — los agentes son, esencialmente, modelos de lenguaje equipados con herramientas y la capacidad de planificar.
Lo que nadie te dice sobre los modelos de lenguaje
Hay una pregunta que sobrevuela cualquier explicación honesta sobre esta tecnología, y que casi nadie plantea directamente porque incomoda: ¿los modelos de lenguaje realmente entienden lo que procesan?
La distinción que lo cambia todo: predecir no es comprender
Un modelo de lenguaje genera la continuación más probable de un texto. Lo hace extraordinariamente bien — tan bien que el resultado parece comprensión. Pero hay una diferencia filosófica y técnica entre predecir qué palabras siguen y entender el significado de lo que se está diciendo.
En 2021, la lingüista Emily Bender y sus colegas introdujeron el concepto del “loro estocástico” para describir este fenómeno: un sistema que genera texto estadísticamente coherente sin necesariamente tener ninguna representación del mundo al que ese texto hace referencia. No sabe que “agua” es algo que puedes beber, que “dolor” implica una experiencia subjetiva o que “mañana” es un concepto temporal que existe fuera del texto.
Esto no invalida la utilidad de los modelos. Pero sí cambia cómo deberías interpretarlos. Cuando un modelo de lenguaje genera una respuesta incorrecta con total seguridad, no está “mintiendo” — está produciendo el texto más probable sin mecanismo interno para distinguir la verdad de la plausibilidad.
Las capacidades emergentes que nadie sabe explicar del todo
El lado opuesto de esa misma moneda también es inquietante: a partir de cierta escala, los modelos de lenguaje muestran capacidades que nadie diseñó explícitamente y que nadie sabe explicar completamente. Razonan en cadena, resuelven analogías complejas, generalizan a situaciones no vistas durante el entrenamiento. ¿Es eso comprensión? ¿O es predicción estadística tan sofisticada que se vuelve indistinguible de la comprensión desde fuera?
La respuesta honesta es que no lo sabemos. Y esa incertidumbre no es una debilidad de la explicación — es el estado real del conocimiento científico sobre estos sistemas.
"Estamos construyendo sistemas cuyas capacidades emergentes no podemos predecir ni explicar completamente. Eso es un hecho técnico, no una metáfora."
Síntesis de debates en la comunidad de investigación de IA, recogidos en publicaciones de NeurIPS y ICML 2024–2025

Entender cómo funciona la herramienta es la forma más inteligente de usarla
Los modelos de lenguaje son la base tecnológica de casi todo lo que llamamos “inteligencia artificial” hoy. Comprender cómo funcionan — tokens, predicción, entrenamiento, atención — no es trivia técnica. Es el mapa que te permite navegar este ecosistema con criterio en lugar de a ciegas.
Tres ideas para llevarte: primero, un modelo de lenguaje predice, no busca ni recuerda — eso explica tanto su potencia como sus alucinaciones. Segundo, la pregunta de si “entiende” está genuinamente sin responder — y esa incertidumbre importa más de lo que parece. Tercero, sus límites son estructurales, no errores a corregir: fechas de corte, cálculos, información en tiempo real — sabiendo esto, sabes cuándo confiar y cuándo verificar.
El conocimiento de cómo funciona una herramienta nunca la hace menos útil. La hace más útil, porque sabes exactamente qué pedirle y qué no. La próxima vez que uses un chatbot, ya no estarás frente a una caja negra misteriosa. Estarás usando un predictor de texto extraordinariamente sofisticado — lo cual, bien pensado, sigue siendo algo bastante asombroso.
Si quieres ver esta tecnología en acción de forma práctica, nuestra guía sobre los mejores chatbots de IA gratuitos en 2026 te ayuda a elegir cuál usar para cada tipo de tarea — ahora con una comprensión real de qué hay detrás de cada uno.
Preguntas frecuentes sobre los modelos de lenguaje
¿Qué diferencia hay entre un modelo de lenguaje y ChatGPT?
ChatGPT es una aplicación construida sobre un modelo de lenguaje — específicamente sobre la familia de modelos GPT de OpenAI. La relación es similar a la de un motor y un automóvil: el motor (el modelo de lenguaje) es la tecnología base; el automóvil (ChatGPT) es el producto diseñado para que las personas lo usen. Claude, Gemini y otros chatbots también son aplicaciones construidas sobre sus propios modelos de lenguaje grande. El modelo es la tecnología; el chatbot es la interfaz que la hace accesible.
¿Los modelos de lenguaje tienen acceso a internet en tiempo real?
Por sí solos, no. Un modelo de lenguaje puro solo tiene acceso a lo que aprendió durante su entrenamiento, que tiene una fecha de corte. Lo que sí pueden hacer algunos sistemas es integrar herramientas de búsqueda externas — como hace Perplexity de forma nativa, o como hacen ChatGPT y Gemini cuando activas la búsqueda web. Esa capacidad no es del modelo en sí: es una herramienta adicional que el sistema puede invocar para obtener información actualizada y luego procesarla con el modelo de lenguaje.
¿Por qué los modelos de lenguaje a veces inventan información falsa?
Porque su objetivo es generar el texto más probable, no el más verdadero. Este fenómeno se llama “alucinación”. El modelo no tiene un mecanismo interno para distinguir entre algo que aprendió de fuentes confiables y algo que infiere de patrones estadísticos. Ambos tipos de output se generan con el mismo proceso — y suenan igual de seguros. Las alucinaciones son más frecuentes en información específica: fechas, cifras, nombres propios, citas textuales. Para este tipo de datos, siempre vale la pena verificar en una fuente independiente.
¿Qué es un modelo de lenguaje grande (LLM) exactamente?
Un LLM (Large Language Model) es un modelo de lenguaje de escala masiva — entrenado con billones de tokens de texto usando arquitecturas Transformer y miles de millones de parámetros ajustables. La diferencia con modelos anteriores no es solo cuantitativa: a partir de cierto umbral de escala, los LLM muestran capacidades emergentes que los modelos más pequeños no tienen — razonamiento complejo, generalización a tareas no vistas, comprensión de contextos extensos. GPT-4o, Claude Sonnet, Gemini Pro son ejemplos de LLM actuales.
¿Es lo mismo un modelo de lenguaje que la inteligencia artificial general?
No. La inteligencia artificial general (AGI) se refiere a un sistema hipotético capaz de realizar cualquier tarea cognitiva que pueda hacer un humano, con la misma flexibilidad y comprensión. Los modelos de lenguaje actuales, por muy capaces que sean en tareas lingüísticas, tienen limitaciones estructurales claras: no tienen experiencia del mundo físico, no aprenden continuamente de nuevas experiencias y su “comprensión” sigue siendo objeto de debate científico. Son herramientas extraordinariamente potentes para tareas específicas — no inteligencia general.
¿Cuánto cuesta entrenar un modelo de lenguaje grande?
El costo de entrenar los modelos más grandes es astronómico y solo está al alcance de grandes empresas tecnológicas e instituciones con recursos significativos. Estimaciones para modelos como GPT-4 hablan de costos de entrenamiento de entre 50 y 100 millones de dólares, aunque las cifras exactas no son públicas. Esto no significa que todos los modelos sean igual de costosos: los modelos más pequeños y especializados pueden entrenarse con recursos mucho más modestos, y el costo por capacidad ha bajado significativamente en los últimos dos años gracias a mejoras en eficiencia de entrenamiento.
Héctor Nexo es especialista en inteligencia artificial aplicada a negocios digitales. Con experiencia en automatización, marketing con IA y productividad para emprendedores, fundó Portal Digital 21 para ayudar a profesionales y empresas a entender y aprovechar las herramientas de IA que están transformando el mundo digital. Su enfoque es práctico, directo y sin tecnicismos innecesarios.




