

¿Cómo aprende la IA sola? La explicación definitiva
¿Cómo aprende la IA sola? Imagina que le dices a un niño de cinco años: “aprende a distinguir perros de gatos” y en lugar de explicarle nada, simplemente le muestras diez millones de fotografías. Sin reglas. Sin instrucciones. Solo imágenes. A los pocos días, ese niño no solo distingue perros de gatos con una precisión asombrosa: puede identificar razas, detectar animales en entornos complejos y hacer distinciones que ningún adulto le enseñó explícitamente. Eso, con matices importantes, es aproximadamente lo que hace la inteligencia artificial cuando aprende.
La pregunta de cómo aprende la inteligencia artificial sola es una de las más buscadas y, paradójicamente, una de las peor respondidas. Los medios oscilan entre dos extremos: quienes la presentan como una magia incomprensible y quienes la reducen a fórmulas matemáticas que solo los especialistas pueden entender. Ninguno de los dos extremos te sirve si quieres, de verdad, comprender qué está pasando.
Este artículo toma otro camino. Aquí vas a entender el mecanismo real por el que una máquina puede aprender a reconocer tumores en radiografías, traducir idiomas, componer música o predecir el precio de una acción, sin que ningún ingeniero le haya explicado directamente cómo se hace cada cosa. Y lo vas a entender sin necesitar un doctorado.

La diferencia entre programar y aprender: por qué importa
Para entender cómo aprende la IA, primero hay que entender en qué se diferencia de la programación tradicional. Y esta distinción es más profunda de lo que parece.
En la informática clásica, un programador escribe reglas explícitas. Si un correo contiene las palabras “oferta especial” y “haz clic aquí” y viene de una dirección desconocida, márcalo como spam. La lógica está escrita. La máquina la sigue. No aprende nada: simplemente ejecuta instrucciones.
El problema es que este modelo tiene un techo bajo. El mundo real es demasiado complejo para ser capturado por reglas escritas a mano. ¿Cómo le explicas a un programa con instrucciones fijas que reconozca la tristeza en la voz de una persona? ¿Cómo le describes en código qué es exactamente “un perro”? Las excepciones, los contextos y los matices hacen que las reglas explícitas se quiebren con rapidez.
El aprendizaje automático invierte este proceso. En lugar de escribir reglas, le das a la máquina miles o millones de ejemplos y dejas que ella descubra las reglas por sí misma. El ingeniero no dice “esto es un perro porque tiene cuatro patas y pelo”. La máquina extrae sus propios patrones de los datos. Y esos patrones suelen ser muchísimo más sofisticados y precisos que cualquier cosa que un humano podría escribir a mano.
Clave conceptual – En la programación clásica: reglas + datos = respuesta. En el aprendizaje automático: datos + respuestas = reglas. Esta inversión lo cambia todo.
¿Por qué llamarlo “aprendizaje”?
La palabra “aprendizaje” es una metáfora, y como toda metáfora, ilumina algunas cosas y oscurece otras. La IA no aprende como aprende una persona: no experimenta, no siente curiosidad, no construye significados. Pero sí hace algo funcionalmente parecido: modifica su comportamiento en función de la experiencia pasada para mejorar en el futuro. Y esa capacidad de mejorar a partir de ejemplos es lo que justifica el término.
Cómo aprende la inteligencia artificial sola: el ciclo fundamental
El proceso por el que una IA aprende puede resumirse en un ciclo que se repite millones de veces. Comprender este ciclo es la clave para entender casi todo lo que sucede detrás de ChatGPT, los sistemas de recomendación de Netflix o los algoritmos que detectan fraudes bancarios.

Paso 1: Los datos como punto de partida
Todo comienza con datos. Imágenes, textos, sonidos, números, registros médicos, conversaciones, partidas de ajedrez. Sin datos, no hay aprendizaje posible. La IA no puede aprender en el vacío: necesita una materia prima a partir de la cual construir patrones.
La cantidad importa, pero la calidad importa más. Un modelo entrenado con diez millones de imágenes mal etiquetadas aprenderá mal. Uno entrenado con un millón de imágenes perfectamente curadas puede superar al primero con facilidad. Este es un punto que muchas explicaciones populares pasan por alto.
Paso 2: La predicción y el error
La red neuronal —que es el tipo de arquitectura detrás de la mayoría de los sistemas modernos de IA— recibe un ejemplo y produce una predicción. Al principio, esa predicción es casi aleatoria: la red no sabe nada todavía. Entonces se compara esa predicción con la respuesta correcta y se calcula el error.
Si la red debía decir “gato” y dijo “perro”, el error es grande. Si debía decir “gato” y dijo “felino”, el error es pequeño. Este error se convierte en la señal de aprendizaje.
Paso 3: El ajuste de los parámetros
Aquí entra el mecanismo más importante: la retropropagación del error (backpropagation en inglés). Este algoritmo, formalizado por Rumelhart, Hinton y Williams en 1986, calcula cómo habría que modificar cada conexión dentro de la red para que el error sea un poco más pequeño la próxima vez.
Una red neuronal tiene millones, o incluso billones, de parámetros: pequeños valores numéricos que determinan cómo la red transforma la información. Cada vez que se ajustan esos parámetros en la dirección correcta, la red mejora un poco. Y si este ciclo se repite con suficientes ejemplos, la red termina siendo extraordinariamente buena en su tarea.
✓ Mejor analogía
Imagina que aprendes a lanzar dardos con los ojos vendados. Alguien te dice después de cada lanzamiento si fuiste a la izquierda o la derecha, arriba o abajo. Con miles de lanzamientos, tu brazo aprende los ajustes necesarios sin que nadie te haya explicado explícitamente la mecánica del lanzamiento. Eso es, en esencia, lo que hace el gradiente descendente.
Los tres grandes tipos de aprendizaje automático
No toda la IA aprende de la misma manera. Existen tres paradigmas principales, y cada uno responde a un tipo diferente de problema y de disponibilidad de datos.
| Tipo de aprendizaje | ¿Qué necesita? | ¿Cómo aprende? | Ejemplo real |
|---|---|---|---|
| Supervisado | Datos etiquetados (con respuesta correcta) | Comparando su predicción con la respuesta correcta | Detectar spam, diagnóstico médico, reconocimiento de voz |
| No supervisado | Solo datos sin etiquetas | Buscando patrones y estructuras por sí sola | Segmentación de clientes, compresión de datos, detección de anomalías |
| Por refuerzo | Un entorno y una función de recompensa | Probando acciones y aprendiendo de las consecuencias | AlphaGo, robots que aprenden a caminar, conducción autónoma |
El aprendizaje supervisado: la forma más común
En el aprendizaje supervisado, un humano etiqueta los datos de entrenamiento. Alguien revisa miles de correos y marca cada uno como “spam” o “no spam”. Esa etiqueta es la respuesta correcta que la IA usará para aprender. La mayoría de las aplicaciones de IA que usamos a diario —desde el reconocimiento facial hasta las transcripciones automáticas— se basan en este paradigma.
El aprendizaje no supervisado: encontrar lo que nadie buscaba
Aquí no hay respuestas correctas. La IA recibe datos y debe descubrir por sí misma qué estructuras o agrupaciones existen. Es el tipo de aprendizaje más cercano a la intuición humana: sin que nadie le diga qué buscar, la máquina encuentra similitudes y diferencias que a veces sorprenden incluso a quienes la desarrollaron.
El aprendizaje por refuerzo: aprender jugando
En este paradigma, la IA no aprende de ejemplos sino de consecuencias. Actúa en un entorno, recibe una recompensa o penalización y ajusta su estrategia. Es el mecanismo que usó AlphaGo para convertirse en el mejor jugador de Go del mundo, superando a campeones humanos que llevaban décadas perfeccionando su juego. Y lo logró jugando millones de partidas contra sí mismo.
Redes neuronales: la arquitectura que lo hace posible
Cuando hablamos de inteligencia artificial moderna, casi siempre estamos hablando de redes neuronales artificiales. Esta arquitectura, inspirada vagamente en el funcionamiento del cerebro biológico, es la responsable de los avances más espectaculares de la última década.
“El aprendizaje profundo ha logrado en una década lo que la inteligencia artificial clásica no pudo conseguir en cincuenta años.”— Yoshua Bengio, Premio Turing 2018, considerado uno de los padres del deep learning
¿Qué es exactamente una red neuronal?
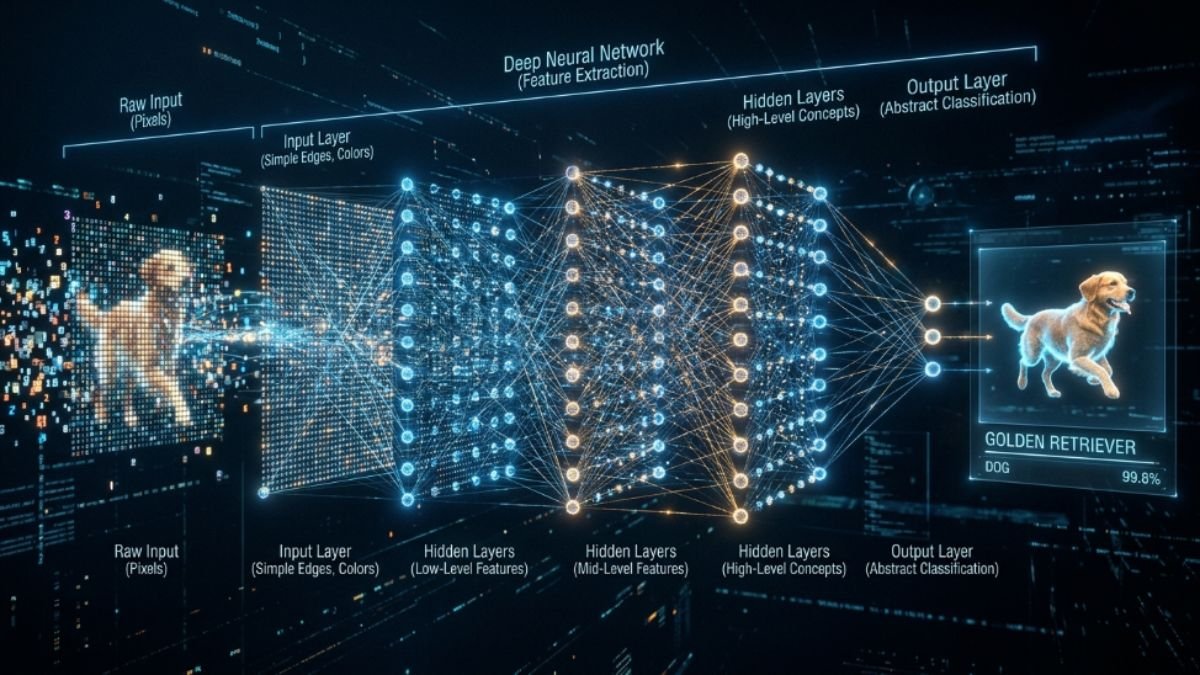
Una red neuronal artificial está compuesta por capas de nodos —también llamados neuronas— conectados entre sí. La primera capa recibe los datos de entrada (por ejemplo, los píxeles de una imagen). Las capas intermedias transforman progresivamente esa información, extrayendo características cada vez más abstractas. La capa final produce la predicción.
En las primeras capas de una red que aprende a reconocer imágenes, las neuronas detectan bordes y contrastes básicos. En las capas intermedias, detectan texturas y formas. En las capas profundas, detectan conceptos como “ojos”, “hocico” o “pelaje”. Nadie programó esas representaciones: emergieron solas del proceso de entrenamiento.
El rol de la profundidad: por qué “deep learning”
El término deep learning —aprendizaje profundo— se refiere precisamente a la profundidad de estas redes: el número de capas intermedias. Las redes modernas como GPT-4 tienen cientos de capas y miles de millones de parámetros. Esa profundidad es lo que permite capturar representaciones tan complejas del lenguaje, la imagen o el sonido.
- Red poco profunda (2-3 capas): Puede aprender patrones simples como clasificar correos por longitud o frecuencia de palabras.
- Red moderadamente profunda (10-20 capas): Puede reconocer objetos en imágenes con precisión aceptable.
- Red muy profunda (100+ capas): Puede entender contexto en el lenguaje, generar texto coherente o diagnosticar enfermedades a partir de imágenes médicas.
⚠️ Atención
Más profundidad no siempre es mejor. Las redes muy grandes requieren enormes cantidades de datos y poder de cómputo, y son más propensas a un problema llamado “sobreajuste”: memorizar los datos de entrenamiento en lugar de aprender patrones generalizables.
El papel de los datos masivos y la computación en el aprendizaje moderno
Si las redes neuronales existen desde los años 50, ¿por qué la revolución del aprendizaje profundo ocurrió recién en la última década? La respuesta tiene dos nombres: datos y poder de cómputo.
El matemático y estadístico Andrew Ng, uno de los investigadores más influyentes en IA, suele usar una metáfora que vale la pena repetir: la inteligencia artificial es como un cohete espacial. Las redes neuronales son el motor. Pero sin el combustible —los datos— y sin la infraestructura de lanzamiento —la computación—, el cohete no va a ningún lado.
La explosión de datos como combustible del aprendizaje
Desde la expansión de internet en los 2000 y el auge de las redes sociales en los 2010, la humanidad comenzó a generar datos en cantidades históricamente sin precedentes. Imágenes, textos, conversaciones, comportamientos, transacciones. Todo ese volumen de información se convirtió en el material de entrenamiento ideal para sistemas de aprendizaje automático.
Para que se tenga una idea de la escala: GPT-4 fue entrenado con aproximadamente un billón de tokens de texto —palabras, fragmentos de palabras, signos de puntuación— recopilados de libros, páginas web, código y otras fuentes. Ningún humano podría leer esa cantidad de texto en mil vidas.
Las GPU y el poder de cómputo
El segundo ingrediente fue el hardware. Las GPUs —unidades de procesamiento gráfico, originalmente diseñadas para videojuegos— resultaron ser extraordinariamente eficientes para realizar los cálculos matriciales que requieren las redes neuronales. Su capacidad para ejecutar miles de operaciones en paralelo aceleró el entrenamiento de modelos en órdenes de magnitud.
Un modelo que en 2010 habría tardado años en entrenarse puede hacerse hoy en días o semanas. Esta reducción del tiempo de cómputo fue lo que desencadenó la era moderna del aprendizaje profundo.
Lo que nadie te dice sobre cómo aprende la IA
Hasta aquí, la narrativa convencional. Lo que sigue es el ángulo que la mayoría de las explicaciones populares omite deliberada o involuntariamente.
La IA no “entiende” lo que aprende
Este es quizás el malentendido más profundo y más extendido. Cuando una red neuronal aprende a reconocer gatos, no desarrolla ninguna comprensión de qué es un gato, qué siente un gato, para qué sirve un gato. Lo que construye son correlaciones estadísticas entre ciertos patrones visuales y la etiqueta “gato”. Si esas correlaciones se rompen —si le muestras un gato en una postura inusual o con una iluminación extrema— el modelo falla con una facilidad que asombra.
Esta distinción entre correlación estadística y comprensión genuina es fundamental para evaluar con honestidad las capacidades y los límites de la IA actual. Los sistemas actuales son extraordinariamente buenos imitando comprensión, pero eso no es lo mismo que comprensión.
El sesgo aprendido: la IA hereda los prejuicios de sus datos
Si entrenamos una IA con datos históricos de contratación laboral en los que los hombres fueron sistemáticamente preferidos para ciertos cargos, la IA aprenderá a preferir a los hombres para esos cargos. No porque sea maliciosa: porque los datos le enseñaron que esa es la “respuesta correcta”. Esto ya ha ocurrido en sistemas reales de selección de personal, de aprobación de créditos y de predicción del riesgo criminal.
La IA no aprende solo los patrones útiles de los datos: aprende todo lo que está en los datos, incluyendo las injusticias históricas que los humanos hemos cometido y registrado.
El conocimiento sin explicación: el problema de la caja negra
Una red neuronal profunda puede decirnos “esta radiografía muestra señales de cáncer de pulmón” con una precisión superior a la de muchos radiólogos. Pero no puede explicarnos por qué llegó a esa conclusión de una manera que un médico pueda verificar o refutar paso a paso. Este problema, conocido como el problema de la “caja negra” o black box, es uno de los grandes desafíos no resueltos de la IA moderna.
Confiamos en que el modelo aprendió lo correcto porque sus predicciones estadísticas son buenas en los datos de prueba. Pero no sabemos con certeza qué aprendió exactamente. Y en dominios donde las decisiones tienen consecuencias serias —medicina, justicia, finanzas—, esa opacidad es un problema real.
⚠️ Reflexión crítica
Cuando una empresa dice que su IA tomó una decisión “objetiva”, lo que en realidad está diciendo es que la decisión emergió de patrones estadísticos en datos históricos. Si esos datos reflejan desigualdades pasadas, la decisión “objetiva” puede ser profundamente injusta.
Cómo aprenden los grandes modelos de lenguaje como ChatGPT
Los modelos de lenguaje como ChatGPT, Claude o Gemini representan una forma específica y reciente de aprendizaje automático que merece una explicación propia. Son la materialización más visible del aprendizaje profundo para el público general, y su funcionamiento tiene algunas particularidades que vale la pena entender.
El preentrenamiento: leer el mundo entero
En una primera fase masiva, el modelo lee cantidades astronómicas de texto y aprende a predecir la siguiente palabra en una secuencia. Parece una tarea simple, pero hacerla bien requiere desarrollar una comprensión implícita de la gramática, los hechos, la lógica, los contextos y las relaciones entre ideas. Es como pedirle a alguien que complete miles de millones de oraciones: para hacerlo bien, necesita entender de qué se está hablando.
El ajuste fino: aprender a ser útil y seguro
Después del preentrenamiento viene una fase llamada fine-tuning o ajuste fino, en la que el modelo aprende a comportarse de maneras específicas. En el caso de los asistentes de IA conversacionales, esto incluye aprender a responder preguntas de forma útil, a rechazar peticiones peligrosas y a mantener un tono adecuado.
Una técnica clave en esta fase es el aprendizaje por refuerzo a partir de retroalimentación humana (RLHF, por sus siglas en inglés). Evaluadores humanos califican diferentes respuestas del modelo, y el modelo aprende a generar respuestas que los humanos prefieren. Es la diferencia entre un modelo que sabe predecir texto y uno que sabe tener una conversación útil.
💡 Dato clave
El entrenamiento de un modelo del tamaño de GPT-4 requiere aproximadamente 25.000 tarjetas gráficas trabajando durante semanas, y consume una cantidad de energía equivalente a la de varios miles de hogares durante un año. El aprendizaje de la IA tiene un costo ambiental real y creciente.
El futuro del aprendizaje en la IA: lo que viene después
El campo del aprendizaje automático está en movimiento constante. Entender adónde se dirige ayuda a contextualizar lo que existe hoy y a evaluar con criterio las promesas y las alarmas que circulan sobre la IA.
- Aprendizaje con menos datos: Los modelos actuales necesitan enormes cantidades de datos para aprender. La investigación en few-shot learning y zero-shot learning busca que los modelos puedan aprender de muy pocos ejemplos, como hace un humano cuando aprende un concepto nuevo.
- Aprendizaje continuo: Hoy, los modelos aprenden en una fase fija y luego se despliegan sin seguir aprendiendo. Los sistemas de aprendizaje continuo buscan que la IA pueda actualizar su conocimiento sin “olvidar” lo que ya sabía, un fenómeno conocido como olvido catastrófico.
- Razonamiento y planificación: Uno de los límites más importantes de los modelos actuales es su dificultad con el razonamiento multistep y la planificación a largo plazo. La siguiente generación de modelos pone un énfasis creciente en estas capacidades.
- Eficiencia energética: Con el costo ambiental del entrenamiento de modelos grandes bajo escrutinio creciente, hay una presión real hacia arquitecturas que aprendan más con menos energía.
La dirección general apunta hacia sistemas que aprendan de maneras más parecidas a cómo aprenden los seres humanos: con menos ejemplos, en entornos dinámicos, combinando aprendizaje con razonamiento. Si ese futuro es posible —y cuándo podría llegar— es todavía una pregunta genuinamente abierta.
Conclusión: lo que cambia cuando entiendes cómo aprende la IA
Comprender cómo aprende la inteligencia artificial no es un ejercicio de curiosidad intelectual: es una herramienta de orientación en un mundo que está siendo transformado por esta tecnología a una velocidad sin precedentes.
Ahora sabes que la IA aprende a través de ciclos de predicción y corrección, ajustando millones de parámetros internos hasta que sus patrones capturan regularidades útiles en los datos. Sabes que ese proceso produce resultados impresionantes pero también heredas sus límites: los sesgos de los datos, la opacidad de los mecanismos y la diferencia fundamental entre correlación estadística y comprensión genuina.
El filósofo Luciano Floridi ha argumentado que la inteligencia artificial no piensa: procesa. No comprende: correlaciona. No siente: optimiza. Esta distinción no disminuye el poder de la tecnología, pero sí nos da un marco más honesto para evaluarla. Un marco que nos protege tanto del miedo irracional como del entusiasmo acrítico.
La próxima vez que uses un asistente de voz, recibas una recomendación de Netflix o veas que una IA diagnostica una enfermedad mejor que un médico, ya sabes qué está ocurriendo debajo de la superficie. Y ese conocimiento, en sí mismo, es una forma de poder.
Si quieres seguir profundizando, en Portal Digital 21 encontrarás análisis sobre qué son los modelos de lenguaje y cómo funcionan, así como una exploración de qué es el machine learning y su impacto en el trabajo cotidiano.
Preguntas frecuentes sobre Cómo aprende la IA sola
¿Puede la inteligencia artificial aprender sola, sin datos proporcionados por humanos?
En la práctica, todos los sistemas de IA actuales requieren algún tipo de intervención humana en su aprendizaje, ya sea en la recopilación de datos, el diseño de la arquitectura o la definición de los objetivos de aprendizaje. El aprendizaje por refuerzo permite que un sistema explore un entorno sin datos etiquetados, pero el entorno y las reglas de recompensa son diseñados por humanos. Una IA completamente autónoma en su aprendizaje sigue siendo, hoy por hoy, una aspiración más que una realidad.
¿Qué diferencia hay entre machine learning e inteligencia artificial?
La inteligencia artificial es el campo general que busca crear sistemas que realicen tareas que normalmente requieren inteligencia humana. El machine learning (aprendizaje automático) es una subcategoría de la IA: el conjunto de técnicas específicas que permiten que una máquina aprenda de datos sin ser programada explícitamente para cada tarea. A su vez, el deep learning (aprendizaje profundo) es una subcategoría del machine learning que usa redes neuronales con muchas capas.
¿Cuánto tiempo tarda una IA en aprender algo?
Depende enormemente de la complejidad de la tarea, la cantidad de datos y el poder de cómputo disponible. Un modelo sencillo de clasificación de texto puede entrenarse en minutos en una computadora personal. Un modelo de lenguaje grande como GPT-4 requirió semanas de entrenamiento en miles de GPUs de alta gama trabajando en paralelo. El tiempo de entrenamiento es uno de los principales cuellos de botella en el desarrollo de sistemas avanzados de IA.
¿La IA puede desaprender algo que aprendió incorrectamente?
Este es uno de los problemas más activos en investigación de IA, conocido como “machine unlearning” (desaprendizaje). En los sistemas actuales, “hacer olvidar” información específica a un modelo entrenado es técnicamente complicado: no basta con eliminar los datos, porque el modelo ya internalizó esos patrones. La solución más común es reentrenar el modelo con datos corregidos, lo que es costoso. Las regulaciones de privacidad como el GDPR están impulsando investigación urgente en este problema.
¿El aprendizaje de la IA es similar al aprendizaje humano?
Hay similitudes superficiales —ambos involucran ajuste gradual a partir de la experiencia— pero las diferencias son profundas. Los humanos aprenden de muy pocos ejemplos, en contextos dinámicos, con comprensión causal y motivación intrínseca. Las redes neuronales requieren millones de ejemplos, aprenden correlaciones estadísticas sin comprensión causal real y no tienen experiencias subjetivas. La analogía con el cerebro biológico que inspiró las redes neuronales es útil como punto de partida, pero engañosa si se toma demasiado en serio.
¿Por qué los modelos de IA cometen errores extraños que un humano no cometería?
Porque la IA aprende correlaciones estadísticas, no principios causales. Un modelo que aprendió a reconocer vacas en fotografías puede fallar completamente si le muestras una vaca en la playa —porque en los datos de entrenamiento las vacas siempre aparecían en prados—. Este tipo de fallo se llama “atajo estadístico” o shortcut learning, y es una consecuencia directa de aprender de patrones superficiales en lugar de entender la realidad subyacente.
Héctor Nexo es especialista en inteligencia artificial aplicada a negocios digitales. Con experiencia en automatización, marketing con IA y productividad para emprendedores, fundó Portal Digital 21 para ayudar a profesionales y empresas a entender y aprovechar las herramientas de IA que están transformando el mundo digital. Su enfoque es práctico, directo y sin tecnicismos innecesarios.




