

¿Qué es un Modelo de Lenguaje Grande (LLM)?
¿Qué es un Modelo de Lenguaje Grande (LLM)?
Hay una ironía silenciosa en todo esto: los modelos de lenguaje grande que ahora escriben poemas, responden correos y asisten en consultas médicas no “entienden” nada en el sentido humano. Y sin embargo, producen textos que nos resultan coherentes, útiles y, a veces, incluso reveladores. ¿Cómo es posible?
La respuesta está en una arquitectura llamada modelo de lenguaje grande, o LLM por sus siglas en inglés (Large Language Model). Es el motor invisible detrás de ChatGPT, Gemini, Claude y docenas de otras herramientas que están redefiniendo lo que significa pensar, crear y comunicarse.
Según el informe AI Index 2025 del Stanford Human-Centered AI Institute, el número de modelos de lenguaje fundacionales publicados creció más del 300% entre 2022 y 2024. Hoy, los LLM procesan miles de millones de consultas diarias en todos los idiomas del mundo. En español —con más de 500 millones de hablantes nativos— esta tecnología está llegando de formas que todavía no terminamos de comprender.
En nuestra experiencia explorando estas herramientas, lo más llamativo no es su capacidad técnica. Es la sensación que producen: la de hablar con algo que parece entender el contexto, el matiz, incluso el humor. Esa sensación merece una explicación honesta, sin exageración ni alarmismo. Aquí vas a entender qué es un LLM desde sus fundamentos, cómo aprende, cuáles son sus límites reales y por qué esta tecnología representa mucho más que una herramienta de productividad.
¿Qué es Exactamente un Modelo de Lenguaje Grande?
Un modelo de lenguaje grande es un sistema de inteligencia artificial entrenado para predecir, generar y manipular texto de forma estadísticamente coherente. La palabra “grande” no es un elogio vago: se refiere a la escala literal del sistema, con miles de millones —o incluso billones— de parámetros ajustados durante el entrenamiento.
La definición más precisa es esta: un LLM es una red neuronal profunda que ha aprendido patrones del lenguaje humano a partir del análisis de cantidades masivas de texto. No aprende reglas gramaticales explícitas. Aprende probabilidades: dado este contexto, ¿qué palabra es más probable que venga después?
La arquitectura transformer: la base de todo
La mayoría de los LLM modernos se construyen sobre una arquitectura llamada transformer, introducida en 2017 en el artículo seminal “Attention is All You Need” de investigadores de Google Brain. Su innovación central fue el mecanismo de atención: la capacidad de pesar la importancia de distintas partes de una oración al procesar cada palabra.
Imagina que lees la frase: “El banco estaba lleno de gente porque el río había desbordado.” El transformer entiende que “banco” aquí no es una institución financiera, sino un espacio junto al agua, porque presta atención a todo el contexto simultáneamente. Eso, que para un adulto es trivial, representó un salto gigantesco en el procesamiento automático del lenguaje.
¿Cuántos parámetros tiene un LLM?
Los parámetros son los valores numéricos que el modelo ajusta durante el entrenamiento para hacer mejores predicciones. GPT-2, de 2019, tenía 1.500 millones de parámetros. GPT-4, lanzado en 2023, se estima en más de 1 billón. Llama 3 de Meta, publicado en 2024, tiene versiones de hasta 405.000 millones de parámetros.
La escala importa, pero no lo es todo. Modelos más pequeños y bien optimizados pueden superar en tareas específicas a modelos masivos. La eficiencia arquitectónica ha demostrado ser tan valiosa como el volumen bruto, lo que ha democratizado el acceso a esta tecnología.
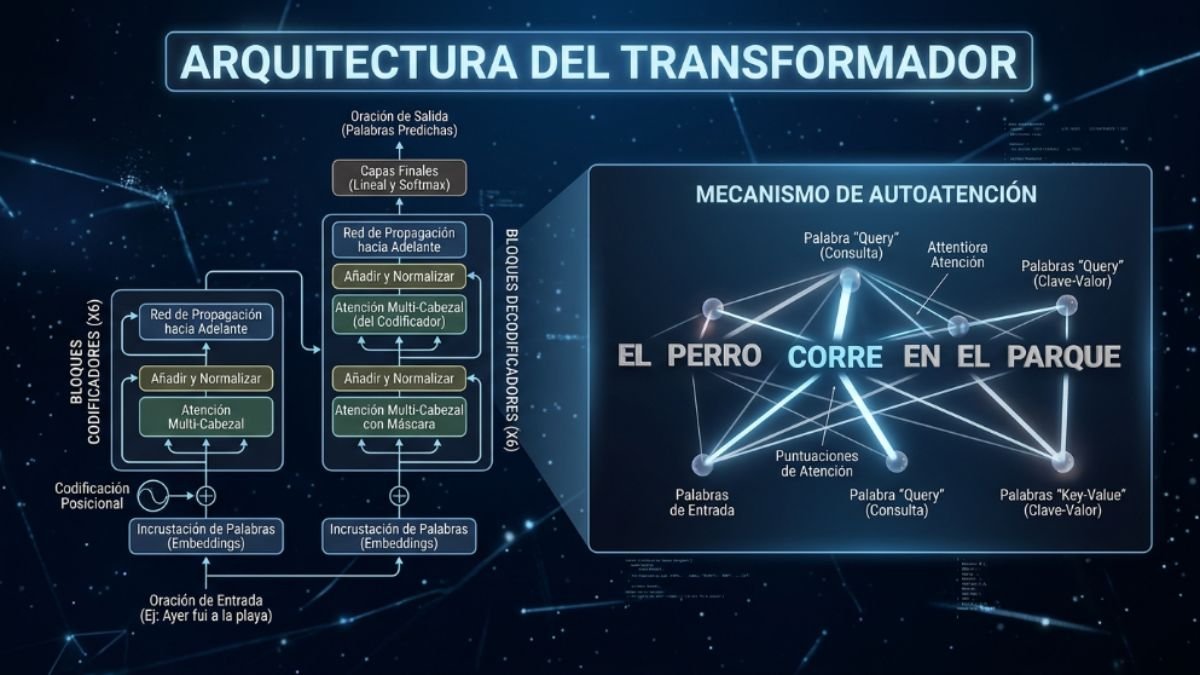
Cómo Aprende un Modelo de Lenguaje Grande: El Proceso de Entrenamiento
Entender cómo aprende un LLM desmitifica gran parte del asombro, y lo reemplaza por una admiración más fundamentada. El proceso ocurre en dos fases principales.
Preentrenamiento: la lectura del mundo
En la primera fase, el modelo consume cantidades enormes de texto: libros, artículos, páginas web, código, foros, conversaciones. Su única tarea es predecir la siguiente palabra. Una y otra vez. Billones de veces.
Este proceso, llamado aprendizaje autosupervisado, no requiere que humanos etiqueten los datos. El texto ya contiene su propia estructura. Al ajustar continuamente sus parámetros para mejorar las predicciones, el modelo desarrolla una representación interna del lenguaje y, con él, del conocimiento humano codificado en ese lenguaje.
Consejo práctico: Cuando interactúas con un LLM, no estás hablando con una base de datos ni con un motor de búsqueda. Estás interactuando con un modelo probabilístico que genera respuestas plausibles basadas en patrones aprendidos, no en “hechos” almacenados. Esa distinción cambia cómo debes evaluar sus respuestas.
Ajuste fino y RLHF: haciendo el modelo útil y seguro
Después del preentrenamiento viene el ajuste fino. Los desarrolladores usan conjuntos de datos más pequeños y curados para orientar el comportamiento del modelo hacia tareas específicas: responder preguntas, seguir instrucciones, mantener conversaciones coherentes.
Una técnica clave es el RLHF (Reinforcement Learning from Human Feedback): evaluadores humanos califican las respuestas del modelo, y esas calificaciones refuerzan comportamientos útiles y penalizan los dañinos. Es un proceso costoso y laborioso, y es en gran parte responsable de que los modelos actuales sean más útiles y menos problemáticos que sus versiones anteriores.
Los LLM Más Importantes que Debes Conocer
El ecosistema de modelos de lenguaje grandes es hoy complejo y muta rápidamente. Estos son los nombres centrales para entender el campo en 2026:
| Modelo | Empresa | Acceso | Destaca en |
|---|---|---|---|
| GPT-4o | OpenAI | API + ChatGPT | Conversación, código, análisis |
| Gemini 1.5 Pro | API + Gemini | Contexto largo, multimodal | |
| Claude 3.5 Sonnet | Anthropic | API + Claude.ai | Razonamiento, redacción |
| Llama 3 | Meta | Open source | Personalización, privacidad |
| Mistral Large | Mistral AI | API | Eficiencia, idiomas europeos |
QUISÁS TE INTERESE SABER: ChatGPT vs Gemini vs Claude: ¿Cuál es Mejor en 2026?
Lo notable de esta tabla es lo que no muestra: la velocidad de evolución. En 2024, el modelo que encabezaba los benchmarks era superado en cuestión de semanas. La carrera entre empresas ha acelerado el desarrollo a una velocidad que pocos analistas anticiparon.
Un dato relevante: el surgimiento de modelos de código abierto como Llama 3 de Meta ha democratizado el acceso a esta tecnología. Hoy es posible ejecutar un LLM capaz en una laptop de gama media. Eso tiene implicaciones profundas para la privacidad, la personalización y la distribución del poder tecnológico.

Las Limitaciones Reales que los Titulares No Cuentan
Los LLM son impresionantes, y también profundamente limitados. Reconocer esas limitaciones no es pesimismo: es rigor intelectual y responsabilidad hacia el lector.
Alucinaciones: cuando el modelo inventa con confianza
Quizás la limitación más conocida es la tendencia a las alucinaciones: generar información falsa con el mismo tono confiado con que produce información verdadera. El modelo no distingue entre lo que sabe y lo que inventa, porque técnicamente no “sabe” ni “inventa” nada. Simplemente predice texto plausible.
Atención: Los LLM pueden citar estudios inexistentes, inventar fechas, nombres o estadísticas. Nunca uses una respuesta de IA sin verificar datos críticos en fuentes confiables, especialmente en contextos médicos, legales o financieros.
El conocimiento tiene fecha de vencimiento
Los modelos se entrenan con datos hasta cierta fecha. Después de ese corte temporal, ignoran eventos, descubrimientos y cambios. Algunos sistemas modernos añaden capacidad de búsqueda web para compensar, pero la base del modelo permanece estática.
No razonan como humanos: reconocen patrones
Existe un debate genuino en la comunidad investigadora sobre si los LLM pueden “razonar” en algún sentido significativo. Lo que sí es claro es que no siguen cadenas lógicas formales. Reconocen patrones en el lenguaje que se parecen al razonamiento, con resultados que a veces son brillantes y a veces son absurdos ante problemas aparentemente simples.
El filósofo John Searle anticipó este problema con su experimento mental de la “Habitación China”: un sistema puede manipular símbolos siguiendo reglas sin comprender su significado. Si los LLM comprenden o solo simulan la comprensión sigue siendo una pregunta abierta —y es una de las más fascinantes de la filosofía de la mente contemporánea.
Usos Prácticos: Dónde los LLM Cambian Algo Real
Más allá de las demostraciones técnicas, un modelo de lenguaje grande está transformando áreas concretas de trabajo y vida cotidiana:
- Redacción y comunicación: borradores de correos, informes, textos de marketing, traducciones y resúmenes. Es el uso más extendido y donde la curva de adopción es más rápida.
- Programación asistida: herramientas como GitHub Copilot han demostrado aumentar la productividad de desarrolladores entre un 30% y un 55% en ciertas tareas, según estudios internos publicados en 2023.
- Educación personalizada: tutores virtuales capaces de adaptar explicaciones al nivel del estudiante y responder preguntas en tiempo real.
- Análisis de información: síntesis de documentos largos, extracción de datos relevantes de grandes volúmenes de texto no estructurado.
- Atención al cliente: sistemas conversacionales con una naturalidad que los bots tradicionales no tenían, liberando tiempo humano para casos complejos.
MÁS INFORMACIÓN AQUÍ: Cómo Automatizar tu Negocio con IA: Guía Completa 2026
Mejor práctica: Cuando uses un LLM en español, reformula prompts complejos si la primera respuesta no satisface. El entrenamiento en inglés es más denso en la mayoría de modelos — entender esa asimetría te permite usar la herramienta más estratégicamente.
Lo que Nadie Te Dice: El LLM como Espejo de Nuestra Civilización
Aquí está la perspectiva que la mayoría de los artículos técnicos omiten, no por descuido, sino porque incomoda.
Un LLM no crea lenguaje desde la nada. Aprende de lo que los humanos ya hemos escrito: todo lo que hemos pensado, debatido, narrado, explicado y distorsionado a lo largo de la historia registrada en texto. En ese sentido, un LLM es el destilado estadístico de nuestra civilización escrita. Y eso tiene implicaciones que van mucho más allá de la productividad.
Primero, los sesgos que contiene el corpus de entrenamiento —raciales, de género, culturales, geopolíticos— se filtran inevitablemente en las respuestas del modelo. No porque el modelo sea malicioso, sino porque el texto humano los contiene. Cuando un LLM asocia ciertos roles con ciertos géneros, o ciertos países con ciertos valores, está reflejando lo que nosotros mismos escribimos. El espejo devuelve una imagen que no siempre queremos ver.
Segundo, el idioma importa más de lo que parece. Los LLM más potentes se entrenaron principalmente en inglés. El español —con toda su riqueza, diversidad regional y producción cultural— está subrepresentado en esos corpus. Cuando un modelo responde en español, en parte está traduciendo conceptos y estructuras pensados en inglés. Hay algo que se pierde en esa traducción. Algo que quizás no podemos medir todavía, pero que intuimos.
“El lenguaje no es simplemente un vehículo del pensamiento; es la condición de posibilidad del pensamiento mismo.” — Noam Chomsky, lingüista y filósofo del lenguaje
Si los sistemas que median nuestra relación con el lenguaje están sesgados hacia ciertos idiomas, culturas y perspectivas, ¿qué significa eso para las formas de pensar que esos sistemas no reflejan bien? ¿Estamos construyendo herramientas que amplifican algunas inteligencias y marginan otras?
No tenemos respuestas definitivas. Pero estas preguntas merecen estar sobre la mesa en cualquier conversación honesta sobre LLM, no solo los benchmarks y las comparativas de velocidad. La próxima vez que uses una de estas herramientas y sientas que algo en la respuesta “no termina de encajar” con tu realidad, quizás no estés equivocado. Quizás simplemente estás percibiendo el límite del espejo.

Conclusión
Los modelos de lenguaje grandes son, sin duda, una de las creaciones tecnológicas más significativas de las últimas décadas. No porque sean inteligentes en el sentido humano —esa discusión sigue abierta— sino porque han demostrado que el lenguaje, con suficiente escala y datos, puede generar comportamientos que parecen inteligentes. Y eso cambia las reglas de muchos juegos.
Entender qué es un LLM es hoy una competencia básica, no un lujo técnico. Saber cómo aprende, qué puede y qué no puede hacer, y qué valores y sesgos contiene, nos convierte en usuarios más conscientes y en ciudadanos mejor preparados para una era en que estas herramientas median cada vez más nuestras decisiones.
Lo más importante que puedes llevarte de este artículo: un LLM no es una fuente de verdad. Es una herramienta estadística extraordinariamente sofisticada. Su valor depende de la calidad de las preguntas que le haces y del criterio con que evalúas sus respuestas. La herramienta no reemplaza el pensamiento crítico. Lo necesita.
¿Te has preguntado alguna vez qué parte de lo que “sabe” un LLM viene directamente de textos que tú u otros hispanohablantes escribieron —y qué parte es una traducción cultural que no termina de capturar nuestra realidad?
Preguntas Frecuentes sobre ¿Qué es un Modelo de Lenguaje Grande (LLM)
¿Qué diferencia hay entre un LLM y la inteligencia artificial general (AGI)?
Un LLM es un sistema especializado en lenguaje: comprende y genera texto de forma sofisticada, pero no tiene conciencia, propósitos propios ni capacidad de aprender nuevas tareas sin reentrenamiento. La AGI sería capaz de razonar y aprender en cualquier dominio como lo hace un humano. Los LLM actuales están muy lejos de ser AGI, aunque representan un avance significativo según algunos investigadores del campo.
¿Los LLM pueden cometer errores graves?
Sí, y esto es crítico entenderlo. Los LLM pueden generar información incorrecta con total confianza —un fenómeno llamado alucinación. Pueden inventar citas, estadísticas, nombres o eventos que nunca ocurrieron. Para decisiones importantes en salud, finanzas o cuestiones legales, siempre verifica la información en fuentes primarias confiables antes de actuar.
¿Cuánto cuesta usar un LLM?
Las versiones gratuitas de ChatGPT, Gemini y Claude ofrecen capacidades limitadas. Las versiones de pago rondan los 20 dólares mensuales para usuarios individuales. Para desarrolladores que acceden por API, el costo se calcula por tokens y puede variar desde fracciones de centavo hasta varios dólares por consulta compleja, según el modelo elegido y el volumen de uso.
¿Los LLM entienden el español igual que el inglés?
No al mismo nivel. La mayoría de los grandes modelos se entrenaron con corpus dominados por el inglés, donde el español está subrepresentado. Sin embargo, modelos como GPT-4o, Claude 3.5 Sonnet y Gemini 1.5 Pro muestran un rendimiento en español que en muchos contextos es prácticamente equivalente al inglés, especialmente en tareas generales de redacción y análisis.
¿Un LLM puede reemplazar a un buscador como Google?
Son herramientas complementarias, no equivalentes. Un LLM genera texto plausible basado en patrones aprendidos y no recupera páginas en tiempo real (salvo integración de búsqueda). Google indexa información actualizada con fuentes verificables. El LLM es mejor para síntesis y razonamiento conversacional; Google es mejor para información reciente. Combinarlos es más poderoso que elegir uno.
¿Qué significa que un LLM sea de código abierto?
Un LLM de código abierto —como Llama 3 de Meta— tiene sus parámetros entrenados disponibles públicamente para descargar, modificar y ejecutar localmente. Esto permite mayor privacidad, personalización y transparencia, aunque requiere infraestructura computacional significativa. Los modelos propietarios como GPT-4 o Claude son accesibles solo vía API, con mayor facilidad de uso pero menos control.
¿Aprenden los LLM de mis conversaciones en tiempo real?
No aprenden en tiempo real. El aprendizaje ocurre en ciclos de reentrenamiento planificados, no de forma continua. Algunas plataformas pueden usar conversaciones para mejorar futuros modelos, aunque esto generalmente puede desactivarse en la configuración de privacidad de cada servicio.
Héctor Nexo es especialista en inteligencia artificial aplicada a negocios digitales. Con experiencia en automatización, marketing con IA y productividad para emprendedores, fundó Portal Digital 21 para ayudar a profesionales y empresas a entender y aprovechar las herramientas de IA que están transformando el mundo digital. Su enfoque es práctico, directo y sin tecnicismos innecesarios.




